Create Predicted Eventlog
This article has instructions how to install, configure and use eventlog predictions. The prediction creates a new model that contains the source model data and the predictions. It's able to predict case attributes for the generated new cases and event attributes for the predicted events. To distinguish the real (source data) and predicted events and cases, there are following attributes in the model:
- Event attribute Predicted denotes whether the event is from the source data (false) or whether it's predicted (true).
- Case attribute Generated denotes whether the case is in the source data (false) or whether the prediction generated it as a new case (true).
Prerequisites for prediction
Following prerequisites need to be fulfilled to run the eventlog prediction:
- QPR ProcessAnalyzer 2024.8 or later in use
- Snowflake connection is configured
- Source models are stored to Snowflake
Install prediction to Snowflake
To install the eventlog prediction to Snowflake:
- Go to Snowflake, and create a Snowflake-managed stage with name PREDICTION to the same schema configured to QPR ProcessAnalyzer (in the Snowflake connection string). Use settings in the following image:
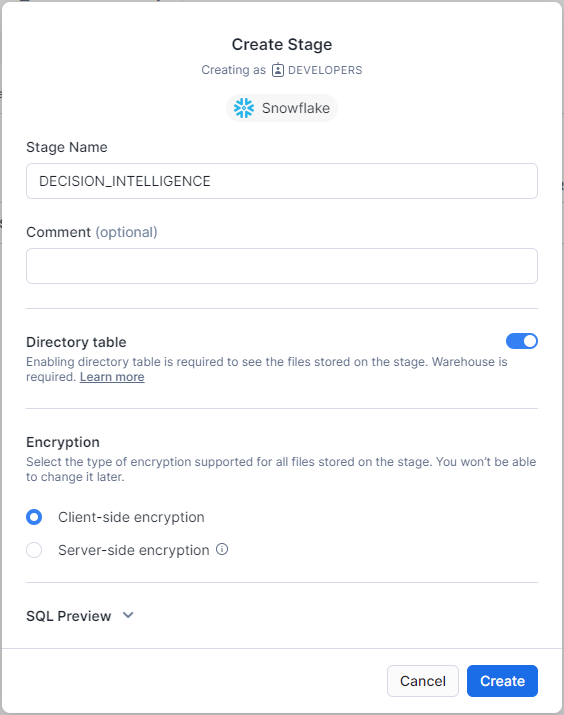
- Open the created stage and upload the predict.pyz file into the stage (ask the file from your QPR representative).
- Create the following procedure to the same schema:

CREATE OR REPLACE PROCEDURE MARKKU_HINKKA.QPRPA.QPRPA_SP_PREDICTION_MARHINK("CONFIGURATION" OBJECT)
RETURNS OBJECT
LANGUAGE PYTHON
STRICT
RUNTIME_VERSION = '3.11'
PACKAGES = ('nltk','numpy','networkx','pandas','scikit-learn','snowflake-snowpark-python','tensorflow==2.12.0','dill','psutil','prophet','holidays','python-kubernetes','docker-py','cryptography')
HANDLER = 'main'
EXECUTE AS OWNER
AS '
import sys
def main(session, parameters_in: dict) -> dict:
session.file.get(''@decision_intelligence/predict_marhink.pyz'', ''/tmp'')
sys.path.append(''/tmp/predict_marhink.pyz'')
import predict
return predict.main(session, parameters_in)
';
Create prediction script in QPR ProcessAnalyzer
1. Create the following example expression script (e.g., with name Create prediction model):
let sourceModel = ProjectByName("<project name>").ModelByName("<model name>");
let completeCaseEventTypeName = "<event type name found only in complete cases>";
let targetProject = Project;
let eventTypeColumnName = sourceModel.EventsDataTable.ColumnMappings["EventType"];
_system.ML.GeneratePredictionModel(#{
"Name": "My prediction model", // Name of the PA model to generate ti the target project.
"SourceModel": sourceModel, // Snowflake-based PA model used for training the prediction model.
"TargetProject": targetProject, // Target project to create the model into.
"TrainingConfiguration": #{ // Training parameters.
"num_epochs_to_train": 200
},
"GenerationConfiguration": #{ // Model generation parameters.
"cases_to_generate": 1000
},
"TrainingDataFilter": #{
"Items": [
#{
"Type": "IncludeCases",
"Items": [
#{
"Type": "EventAttributeValue",
"Attribute": eventTypeColumnName,
"StringifiedValues": [
`0${completeCaseEventTypeName}`
]
}
]
}
]
},
"IncompleteCasesFilter": #{
"Items": [
#{
"Type": "ExcludeCases",
"Items": [
#{
"Type": "EventAttributeValue",
"Attribute": eventTypeColumnName,
"StringifiedValues": [
`0${completeCaseEventTypeName}`
]
}
]
}
]
},
"RecreatePredictionModel": true, // Should a prediction model be overwritten if one already exists for this source model and target model name combination.
"TrainingCaseSampleSize": 10000 // Maximum number of cases to use from the source model (random sampled).
});
2. Configure prediction for the previously created script as instructed in the next chapter. At minimum, replace the tags listed below with some suitable values:
- <project name>: Name of the project in which the source model is located.
- <model name>: Name of the model to be used as source model. This data in this source model will be used to train the prediction model so that it can generate new cases and continuations for incomplete existing cases.
- <event type name found only in complete cases>: This example script has been hard-coded to determine whether a case is complete or incomplete based on the existence of this event type.
Configure prediction
Prediction script has the following settings in the GeneratePredictionModel call:
- Name: Name of the QPR ProcessAnalyzer model that is created to the target project. The model will contain the source model content and the predictions.
- SourceModel: Source model for which the prediction is made. Model can be selected for example based on id with ModelById function or by name with ModelByName function.
- TargetProject: Target project to create the new model into.
- RecreatePredictionModel: When true, a new ML model is trained when the script is run. When false, the prediction is run using possibly pre-existing ML model.
- TrainingConfiguration: Training parameters.
- attributes: Attribute configurations (for more information, see the chapter below).
- generate_start_time_trend_images: If set to true, two images will be generated for each cross validated Prophet-parameter combination and also for the final selected parameters showing the results of plot and plot_components-functions.
- The images will be generated into stage files with the following path names:
- plot: @decision_intelligence_testing/{model_name}_st_RMSE={rmse_value or "final"}.png
- plot_components: @decision_intelligence_testing/{model_name}_st_RMSE={rmse_value or "final"}_comp.png
- The default value is false.
- The images will be generated into stage files with the following path names:
- max_num_case_clusters: Set the maximum number of clusters to divide the case attribute values into.
- The default value is 20.
- max_num_traces_in_training: Set the maximum number of traces used in training.
- When training, every case of length N will be split into N traces (a.k.a. prefixes) (p_1, ..., p_N), where p_x contains first x events of the all events of the full case.
- If there are more traces available than this configured value, cases to include will be random sampled so that the maximum is exceeded by at most one case.
- If null, all the traces will be used, no matter what (may easily lead to running out of memory).
- The default value is 100000.
- When training, every case of length N will be split into N traces (a.k.a. prefixes) (p_1, ..., p_N), where p_x contains first x events of the all events of the full case.
- num_epochs_to_train: How many times the training set is used in training. The best performing model out of all the iterations will be selected.
- The default value is 500.
- num_extra_years_to_reserve_in_created_model: Number of additional years after the year of the last timestamp in the training data to reserve to the capacity of the created ML model, allowing the model to be able to predict timestamps in the range between the minimum timestamp year in the training data and the maximum timestamp year plus this value.
- The default value is 20.
- reserve_extra_sequence_length: How many extra events to reserve space for in the ML model compared to the number of events the longest case in the training data has.
- The default value is 5.
- samples_per_epoch: If not null, specifies (approximately) how many traces/prefixes will be used to represent one epoch of data in the training. The actual value used will be made divisible by batch_size using this formula:
- max(floor(samples_per_epoch / batch_size), 1) * batch_size
- If null, every epoch will use all the traces/prefixes in the training data.
- The default value is null
- validation_split: Percentage of traces/prefixes to use to evaluate the loss and any model metrics at the end of each epoch. The model will not be trained on this data.
- If 0, separate validation data will not be used. Instead, all the training data will be used also as validation data.
- The default value is 0.
- GenerationConfiguration: Event generation parameters. When null, no generation is done. For example, following parameters are supported:
- avoid_repeated_activities: Array of activity names that should occur at most once in any case. The probability of selecting any of the activities specified in this configuration more than once is set to be 0.
- Empty array means that activity generation is not restricted by this setting at all.
- null value means that there should not be any activities that can occur more than once (shortcut for specifying all the activity names).
- The default value is an empty array.
- cases_to_generate: Maximum number cases to create. The number of created cases is further limited by the capabilities of the trained model and the case_generation_start_time and case_generation_end_time parameters.
- The default value is such that the number of cases, by itself, is not limited.
- case_generation_start_time: If defined, new cases will be generated after this timestamp (given as string in ISO datetime format).
- If undefined, the latest start event timestamp used in the training data is used.
- The default value is undefined.
- case_generation_end_time: If defined, new events and cases will not be generated after this timestamp (given as string in ISO datetime format). E.g., "2015-01-01T00:00:00".
- The default value is unlimited (only limit comes from the capacity of the trained model)
- generate_debug_event_attributes:
- If true, additional columns will be added containing, e.g., probabilities of the selected activity and other activities.
- The default value is false.
- max_num_events:
- Specifies the maximum number of events to generate for any case.
- If unspecified (=default), the value equals to <the maximum number of events in any case in the training data>+<the value of reserve_extra_sequence_length in training>.
- min_prediction_probability :
- The minimum probability of any prediction. If the probability of a prediction is lower than this, it will never be picked.
- The default value is 0.01.
- temperature:
- If 0, the generated next activity will always be the one that is the most probable.
- If 1, the generated next activity is purely based on the probabilities returned by the trained ML model.
- This behavior is interpolated when using values between 0 and 1.
- The default value is 0.9.
- avoid_repeated_activities: Array of activity names that should occur at most once in any case. The probability of selecting any of the activities specified in this configuration more than once is set to be 0.
- TrainingDataFilter: Filter to select specific cases that are used to train the prediction model. This filter is required to train the model only using the completed cases. Uncompleted cases should not be used for the training, so the model doesn't incorrectly learn that cases should end like that.
- IncompleteCasesFilter: Optional filter to select which cases the prediction is made for. To improve performance of the prediction, it's recommended to include only the incomplete cases for which new events might appear, and skip the completed cases for which new events are not expected anymore.
- TrainingCaseSampleSize: Maximum number of cases to take from the source model (cases are selected randomly). Use a lower setting to speed up the ML model training. The greater the value, the more subtle phenomena the prediction can learn from the data.
Attribute configuration
Attribute configuration is used to configure which event- and case attributes should be used in prediction model and how they are used.
The configuration is in the top level split into two sections: "event" and "case". "Event" is used to configure event attributes, whereas "case" is used for case attributes.
The next level supports one value: "input".
The next level after that, supports the following settings:
- categorical_groups: An array of categorical attribute group configuration objects used to define groups of attributes that will be bundled together in the trained model, either as separate input- or output features. Each attribute group will form its own input- or output vector used in the model training and generation.
- If null, only one group will be created with all the available categorical attributes included.
- The following settings are supported by these objects:
- attributes: An array of attribute names.
- If null, all the input attributes are to be included in this group.
- max_num_clusters: The maximum number of clusters (input- or output vector feature values) to use to represent this group of attributes.
- Default value: 20
- NOTE: Clustering is used by default to convert a set of attribute values into an input- or output vector used by the prediction model.
- attributes: An array of attribute names.
- columns: An array of attribute column configuration objects used to define columns in the input data that are to be used as event- or case attributes.
- If null, all the columns will be included as categorical attributes (except case id, event type (only for event) and timestamp (only for event) columns).
- The following settings are supported by these objects:
- label: Column name.
- type: Type of the column. Supported types are:
- categorical: Values can take on one of a limited, and usually fixed, number of possible values.
- numeric: Value is considered as a continuous numeric value.
Example
Use all event attributes as input for the prediction model. In addition, additional machine learning input vector for SAP_User-event data column supporting at most 10 unique values.
In addition, for case attributes, only "Region", "Product Group", "Account Manager" and "Customer Group" case data columns are used as categorical attributes and "Cost" as numeric attribute. Furthermore, the four categorical case attributes are grouped into three groups, each of which are used as its own input vector for the prediction model.
When generating, all event attributes will be included for generated events as columns. Generated cases will have only "Region", "Product Group", "Account Manager", "Customer Group", and "Cost" columns.
"attributes": #{
"event": #{
"input": #{
"categorical_groups": [
#{
"attributes": None
},
#{
"attributes": ["SAP_User"],
"max_num_clusters": 10
}
],
"columns": None
}
},
"case": #{
"input": #{
"categorical_groups": [#{
"attributes": ["Account Manager"]
}, #{
"attributes": ["Customer Group"]
}, #{
"attributes": ["Region", "Product Group"]
}],
"columns": [
#{ "label": "Region", "type": "categorical" },
#{ "label": "Product Group", "type": "categorical" },
#{ "label": "Account Manager", "type": "categorical" },
#{ "label": "Customer Group", "type": "categorical" },
#{ "label": "Cost", "type": "numeric" }
]
}
}
}